
Contains Nearby Duplicate Window
You are given an array and an integer k. The goal is to decide whether the array contains two equal values whose indices are at most k apart.
This is not asking whether duplicates exist anywhere in the array. The distance between the duplicate positions matters. For example, in [1,2,3,1] with k = 3, the answer is true because the two 1 s are exactly 3 positions apart. But if the allowed distance were smaller, that same duplicate pair might no longer count.
In [1,0,1,1] with k = 1, the answer is also true because the last two values are both 1 and are adjacent. On the other hand, [1,2,3,1,2,3] with k = 2 returns false because every repeated value is too far away from its earlier copy.
So the task is to check for duplicates inside a moving window of size k.
Example Input & Output
Value 1 appears at indices 0 and 3, distance 3.
Last two ones are adjacent.
No duplicate appears within distance 2.
Algorithm Flow
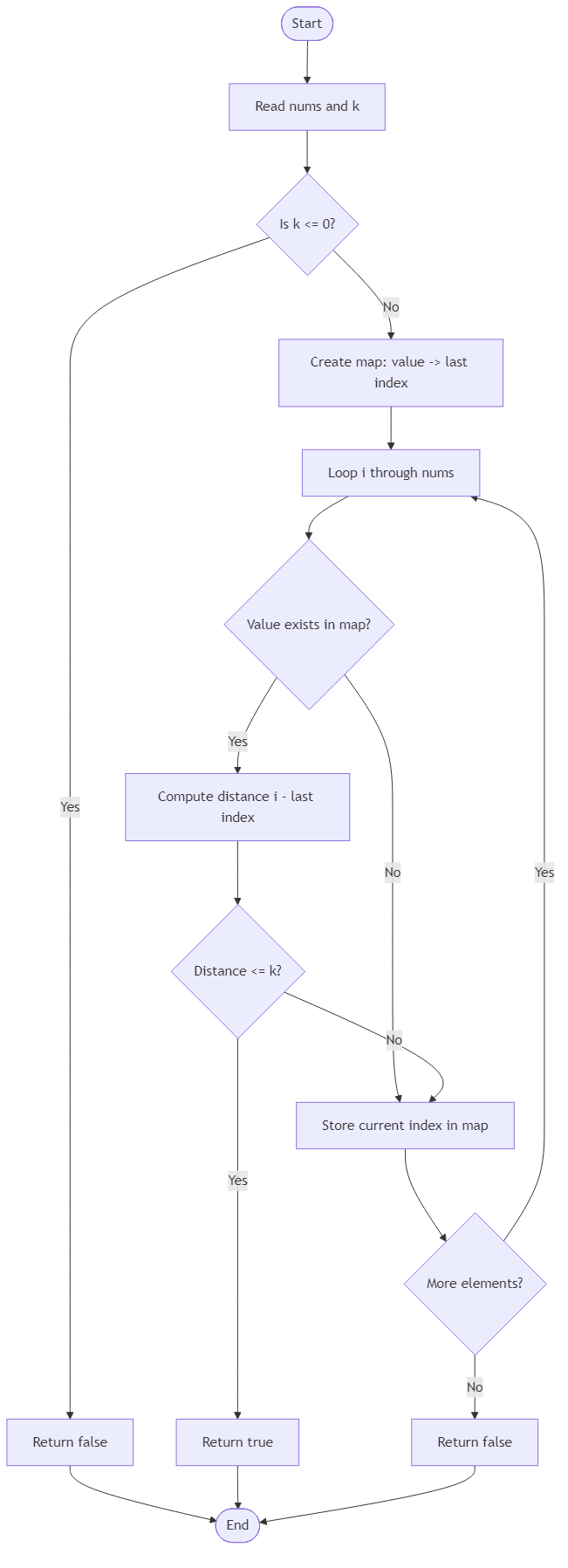
Solution Approach
The sliding-window way to think about this problem is: while scanning the array, keep track of the last k values we have seen. If the current number is already inside that recent window, then we found a duplicate close enough to satisfy the distance rule.
A convenient data structure for that recent window is a set. The set stores the values currently inside the active window, which means membership checks are fast.
As we move from left to right, for each index i:1. If nums[i] is already in the set, return true immediately.2. Otherwise add nums[i] to the set.3. If the window size has now grown beyond k, remove the value that just fell out of range, which is nums[i - k] or equivalently manage the left edge so the set only represents valid nearby indices.
The important part is that the set should only contain elements from the last k positions. That is what makes a repeated value inside the set meaningful: it guarantees the earlier copy is close enough.
It is also worth noticing the edge case k = 0. In that case, no two different indices can be within distance zero, so the answer must be false. The sliding-window logic naturally respects that, because the window never keeps any earlier value available for matching.
This approach is particularly nice because we only care about membership, not counts. The moment a value is found again inside the active window, we already know the answer is true. There is no need to keep full frequency maps unless the problem asked for something more complicated.
This is better than checking every pair of nearby indices with nested loops. A brute-force solution can take O(nk) time, but the sliding-window set approach runs in about O(n) time with O(k) extra space.
The key observation is that the problem is not about all past values. It is only about the values still inside the allowed distance window.
Best Answers
import java.util.*;
class Solution {
public boolean contains_nearby_duplicate_window(int[] nums, int k) {
if (k <= 0) return false;
Map<Integer, Integer> last = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
if (last.containsKey(nums[i]) && i - last.get(nums[i]) <= k) return true;
last.put(nums[i], i);
}
return false;
}
}Comments (0)
Join the Discussion
Share your thoughts, ask questions, or help others with this Challenge.