
Remove Duplicates from Sorted Array
In Remove Duplicates from Sorted Array, you are given an array that is already sorted. Your job is to keep only one copy of each distinct value at the front of the array and return how many unique values remain.
The important advantage is that the array is sorted. Because equal values appear next to each other, you do not need a hash set or nested loops to detect duplicates. You only need to notice when the current number changes from the previous one.
For example, if nums = [1,2,3,4], the answer is 4 because every value is already unique. If nums = [1,1,2], the answer is 2 because the unique values are [1,2]. A larger example like [0,0,1,1,1,2,2,3,3,4] returns 5, because the distinct values are [0,1,2,3,4].
So the task is to compact the sorted array so that each value appears once at the front, then return the count of those unique values.
Example Input & Output
The array already contains unique elements.
The unique elements are [0,1,2,3,4].
The unique elements are [1,2].
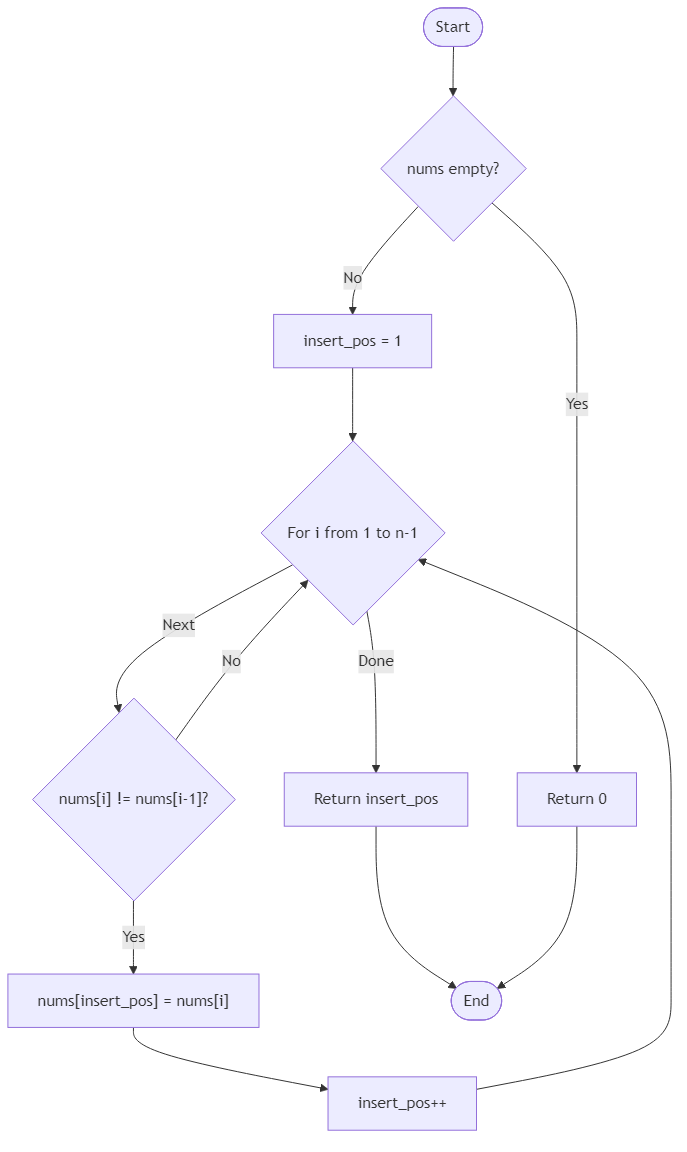
Algorithm Flow
Solution Approach
The standard way to solve this problem is with a two-pointer technique. Since the array is already sorted, duplicates appear in consecutive positions. That means you can scan from left to right and only copy a value forward when it is different from the last unique value you kept.
One pointer can be thought of as the read pointer. It walks through every element in the array. The other pointer is the write pointer. It marks the position where the next new unique value should be stored. At the beginning, the first value is always unique if the array is not empty, so the write pointer can start at index 1.
In JavaScript, the core idea looks like this:
The comparison nums[read] !== nums[read - 1] works because the array is sorted. If the current value is different from the previous one, then it must be the start of a new unique value. You write it into the next available position and move the write pointer forward.
This solution naturally handles all edge cases. If the array is empty, return 0. If the array has one element, return 1. If every element is the same, the write pointer never moves far and the answer becomes 1. If every element is already unique, the write pointer simply ends at the full length of the array.
The time complexity is O(n) because you scan the array once. The extra space complexity is O(1) because the work happens in place and only uses a few variables.
So the full strategy is: use one pointer to read every element, use another to rewrite only the starts of new unique groups, and return the number of unique elements written at the front.
Best Answers
class Solution {
public int remove_duplicates(int[] nums) {
if (nums.length == 0) return 0;
int k = 1;
for (int i = 1; i < nums.length; i++) {
if (nums[i] != nums[i-1]) {
nums[k] = nums[i];
k++;
}
}
return k;
}
}Comments (0)
Join the Discussion
Share your thoughts, ask questions, or help others with this Challenge.